目标检测算法:发展简述与自有工作
前言
目标检测算法从早期传统方法发展到如今的深度学习方法,经历了多次迭代和不断优化,使得精度和模型效率都在持续提高。我在上半年通过优化和迭代目标检测方法,学习了最近的 SOTA 方法和过往的发展路线。下文梳理了深度学习目标检测的发展脉络,并展示了最近自己如何应用这些方法并达到新的性能表现。
深度学习目标检测算法的发展
目标检测算法大致分为两个阶段:传统目标检测算法阶段,以及 2012 年后深度学习目标检测算法的崛起。自 2012 年 AlexNet 在 ImageNet 比赛上出现后,研究者开始把目光转向通过加深神经网络来提升图像语义理解能力。这个方法在图像分类任务上被验证有效后,人们开始尝试其在目标检测上的可行性。深度学习发展至今,目标检测算法又发展出了两条技术路线,分别是 Anchor Based 方法(One-Stage 和 Two-Stage)和 Anchor Free 方法。
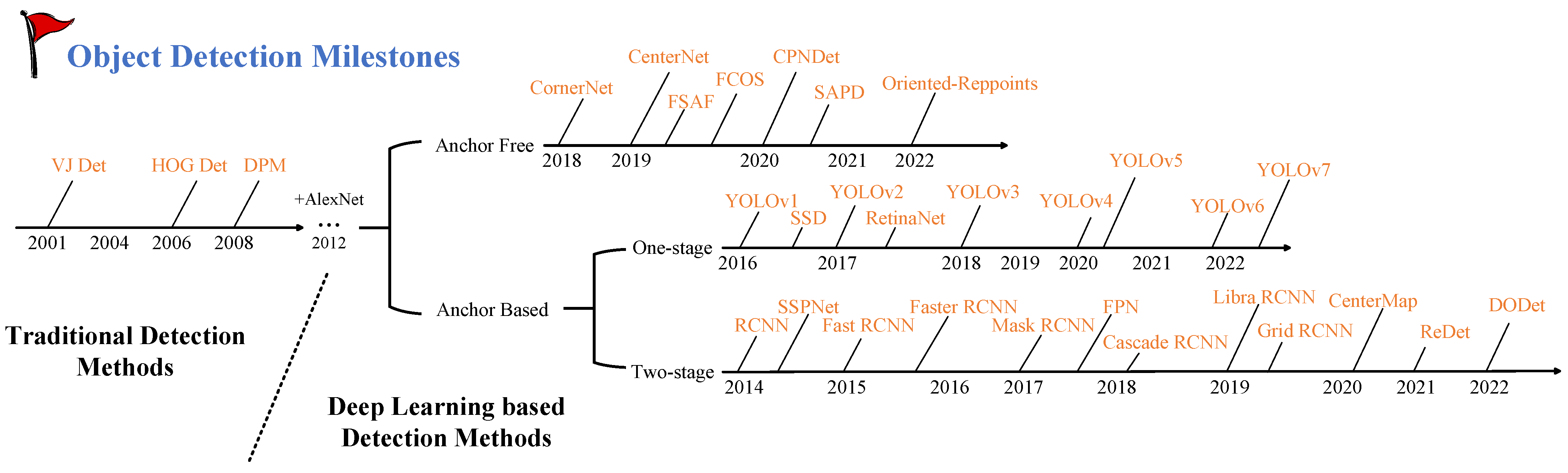
Fig 1. Object Detection Milestones since Millennium.
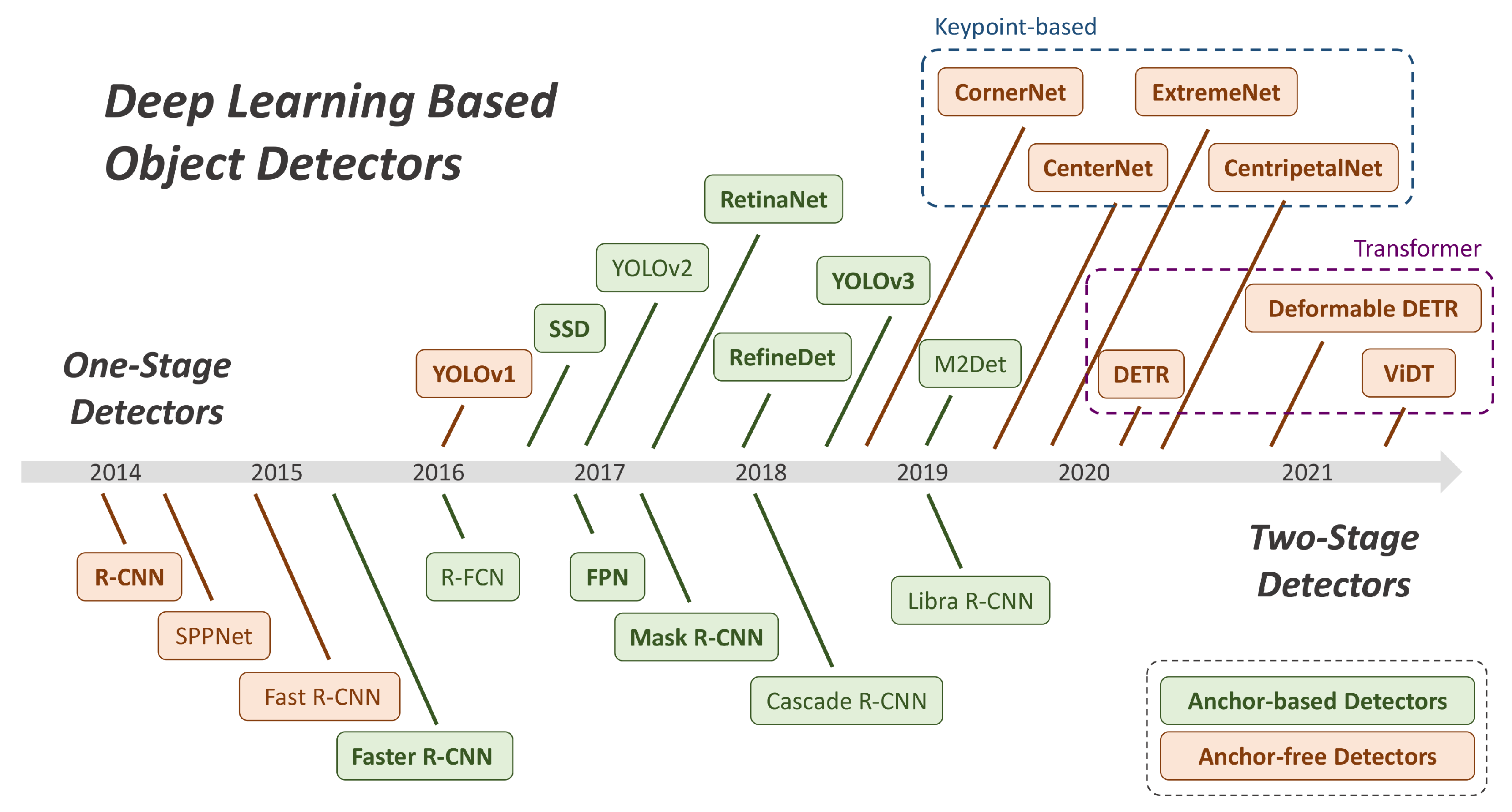
Fig 2. As a supplement of the previous.
目标检测算法主要分为以 YOLO 为主的一阶段检测算法,和以 Mask R-CNN 为代表的二阶段检测算法。2020 年后因为 Transformer 在检测领域上的应用,其优雅的端到端训练方式和巨大的潜力,使得之后的工作主要围绕 DETR 展开。
重要的历史工作
RCNN
这篇深度学习目标检测的开山之作提出了基于区域的概念,是第一次把深度学习图像表征应用到目标检测领域。相较于之前使用手工特征的工作,深度学习面对目标函数有更强的拟合能力。换言之,对于相同物体的不同视角,传统方法需要尽可能设计出更多不同视角的特征模式,而深度学习可以通过对训练素材的特征模式学习拥有一定的泛化能力。
YOLO
这个工作把深度目标检测真正带入工业生产领域,在 GPU 部署下可以达到极高的推理速度。它和后续工作极大满足了工业中的需求,并且因为相对低廉的部署、训练成本,在开源社区中的热度长期不减。
DETR
此前的深度目标检测模型在整个流程中仍需要一些手工操作,如 anchor 的生成和候选框过滤的 NMS 操作。DETR 提出了一种基于 Transformer 的端到端训练、检测流程,摒弃了许多需要人工预设的先验知识,整个流程变得更加优雅、自然和简单。
最新的发展
现在的工作体现出多种趋势,比如把多种任务统一为一种形式,把大规模预训练得到的知识应用在目标检测,以及通过有限标注数据训练更通用的目标检测模型。
文本语言模型方向如 GroundingDINO、GLIP,都结合文本和图像两个模态的预训练模型,在开放集检测、短语定位、零样本迁移等任务中展现了更丰富的能力。
通用目标检测方向如 UniDetector,可以识别开放世界中超过 7000 个类别,并通过对图像和文本空间进行对齐,保证表示具有充分信息量。
我的工作
我们有个任务需要对广告图像上的违规元素或对象进行检测,目前一直在使用 YOLO 模型。我尝试做一个基于自有预训练视觉模型的目标检测模型。接下来把基本背景、参考工作、实验结果和下一阶段想法分享出来。
我们构建了约 12k 张图片、约 200k 实例的有监督目标检测数据集,一共有 65 个类,分别对应业务上的违规元素。同时我们还有一个使用 VQKD 方法和 20m 张无标注图片预训练的 ViT-Base/Large 224/384 模型可选。
这个工作中参考了 DETR、Deformable DETR、DINO DETR、Collaborative DETR、ViTDet 等工作。
在我们训练集、测试集上的结果如下:
| Model | AP.50 (all) | AP.75 (all) | AP.50-.95 (small) | AP.50-.95 (medium) | AP.50-.95 (large) |
|---|---|---|---|---|---|
| YOLOv5l | 0.971 | N.A. | N.A. | N.A. | N.A. |
| Co-deformable (r50_1x) | 0.968 | 0.941 | 0.664 | 0.803 | 0.924 |
| Co-deformable (swin_base_1x) | 0.952 | 0.913 | 0.619 | 0.771 | 0.891 |
| Co-DINO (swin-large-1x-192-fun, 3 epoch setting) | 0.859 | 0.807 | 0.547 | 0.644 | 0.773 |
| Co-DINO (ViT-base-1x-224-vanilla) | 0.899 | 0.843 | 0.482 | 0.664 | 0.837 |
| Co-DINO (ViT-base-1x-224-channel-mapper) | 0.969 | 0.951 | 0.679 | 0.859 | 0.933 |
| Co-DINO (ViT-base-1x-224-sfp) | 0.984 | 0.960 | 0.735 | 0.829 | 0.937 |
从我们的测试数据集上看,模型离线提升不算特别明显,于是又使用新模型做了一个 A/B 测试,粗略估计 mAP 和 mR 平均提升 10%。在不调整数据集的前提下,这种提升仍然相当可观。
下一步计划主要从更好的 ViT 多尺度特征融合,以及 DETR 对小目标检测的能力两个方向继续优化。另外这次实验也发现当前数据集已经不能很好地体现模型优化,后续可能需要重新整理数据集或者补充新增数据。